环境及问题描述:
(1)应用名称:semir-r3-ic
实例ID:
jck-deployment-yacs-25028-25990-2543089-579f5b4846-7ct2n
jck-deployment-yacs-25028-25990-2543089-579f5b4846-9wdm8
jck-deployment-yacs-25028-25990-2543089-579f5b4846-f7gdd
jck-deployment-yacs-25028-25990-2543089-579f5b4846-fs4wb
(2)问题描述:
我们这个服务 4个pod,每个pod都是不间断重启
1、我们排查过 pod的事件:
Readiness probe failed: dial tcp 172.20.18.226:8080: connect: connection refused
Liveness probe failed: dial tcp 172.20.0.222:8080: connect: connection refused
2、查过存在一些 OOM的情况
[9615310.122988] Memory cgroup out of memory: Kill process 12313 (java) score 1962 or sacrifice child [9615310.124707] Killed process 14907 (java), UID 0, total-vm:6764016kB, anon-rss:4149736kB, file-rss:10768kB, shmem-rss:0kB [9624122.418869] java invoked oom-killer: gfp_mask=0xd0, order=0, oom_score_adj=969 [9624122.418874] java cpuset=docker-77c73232cbed801d4e95aaaf02870461134895bb5510cfba3f4098767c41eb6f.scope mems_allowed=0 [9624122.418877] CPU: 0 PID: 14162 Comm: java Kdump: loaded Tainted: G OE ———— T 3.10.0-1062.18.1.el7.x86_64 #1 [9624122.419082] [14156] 0 14156 1679991 1040216 2348 0 969 java [9624122.419096] Memory cgroup out of memory: Kill process 5158 (java) score 1962 or sacrifice child [9624122.420824] Killed process 14156 (java), UID 0, total-vm:6719964kB, anon-rss:4150172kB, file-rss:10692kB, shmem-rss:0kB [9706161.334464] java invoked oom-killer: gfp_mask=0xd0, order=0, oom_score_adj=969 [9706161.334469] java cpuset=docker-89414ff597b6519dc991a37b4973e0c0091fdb208096a72d4d7e6a7deeca935b.scope mems_allowed=0 [9706161.334473] CPU: 13 PID: 7113 Comm: java Kdump: loaded Tainted: G OE ———— T 3.10.0-1062.18.1.el7.x86_64 #1 [9706161.334689] [ 7107] 0 7107 1677293 1041492 2339 0 969 java [9706161.334704] Memory cgroup out of memory: Kill process 15299 (java) score 1963 or sacrifice child
然后做了内存快照,如下: 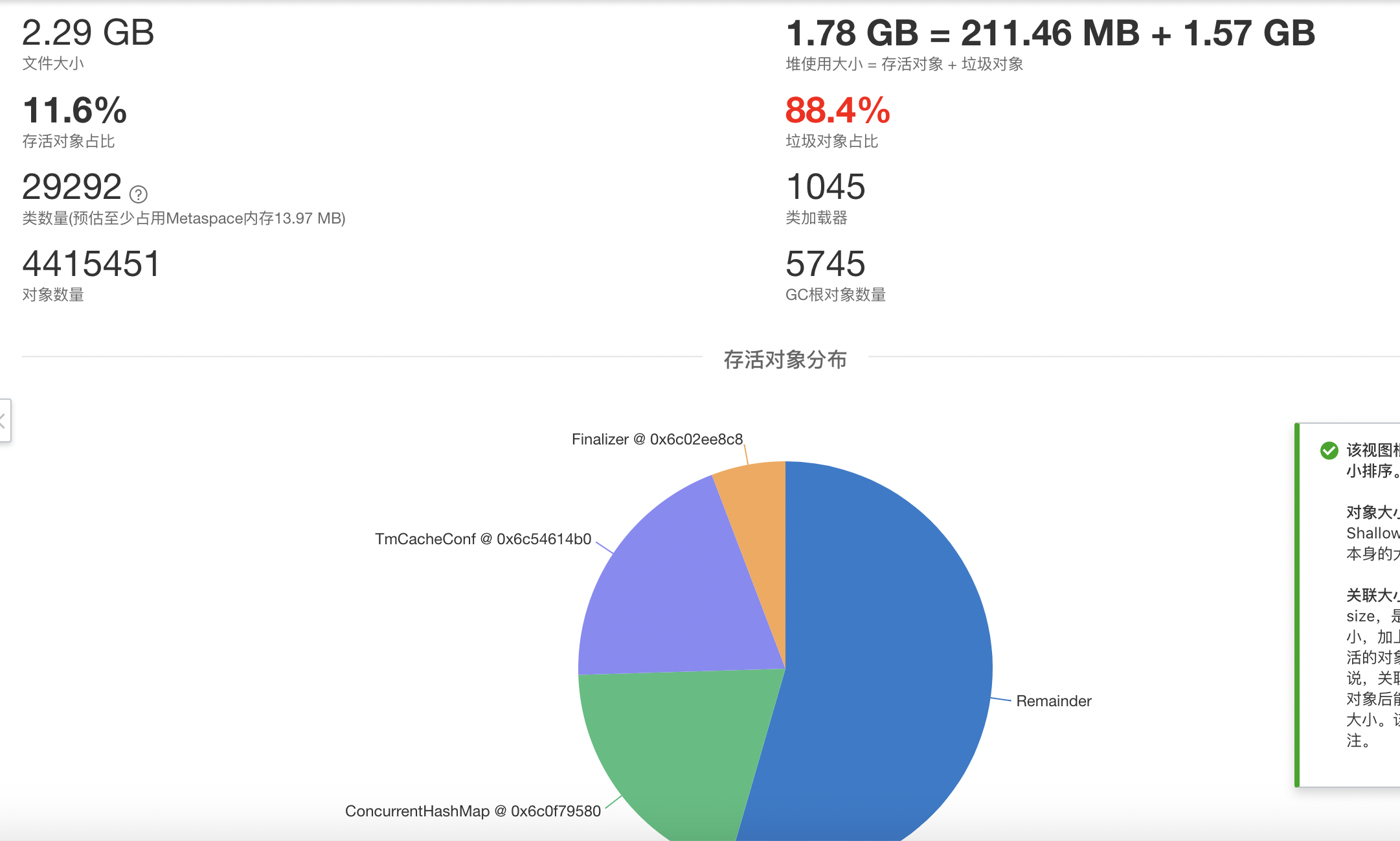
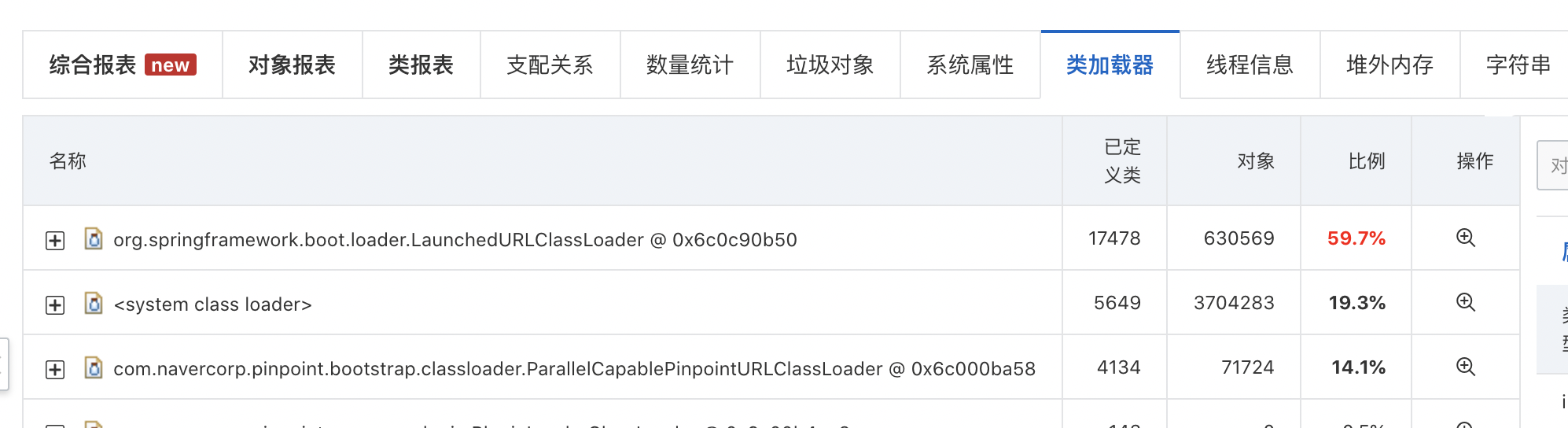
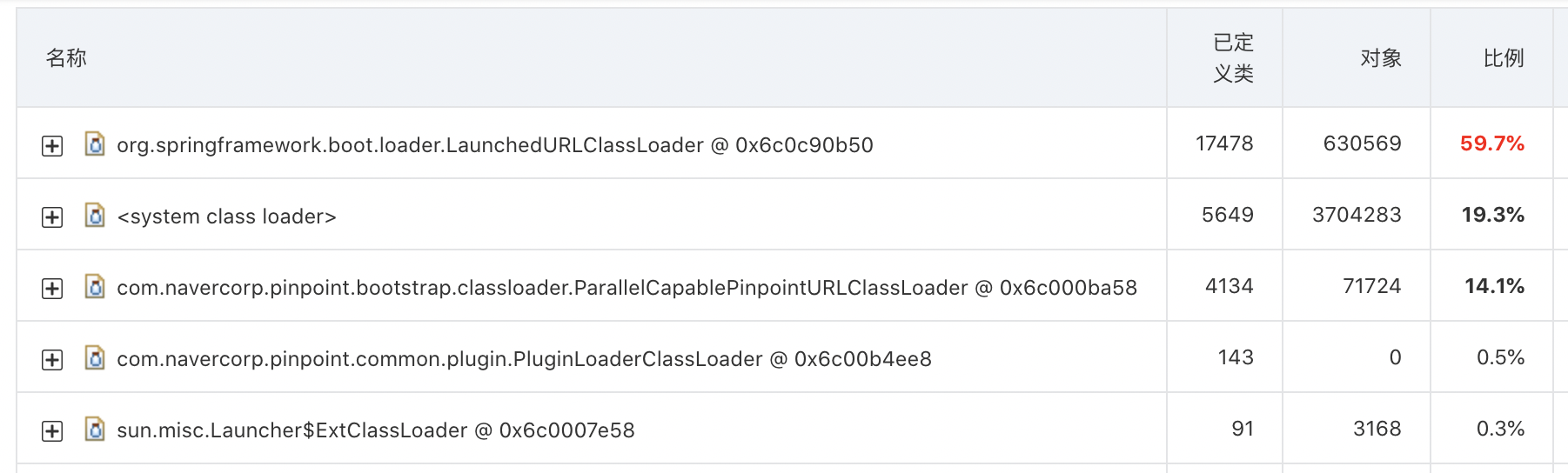
然后就找不到代码的对应关系,不太好分析具体的内存占用过大在哪里,希望帮忙解答下
你可以先定位是[1]还是[2]出了问题,对于问题[1],可以加
-XX:+HeapDumpOnOutOfMemoryError这种参数来抓heapedump然后分析。对于问题[2],可以进POD然后执行top,看java进程的RSS是不是一直涨,直到pod重启,如果是的话,基本上就能确定是[2]这一块出了问题。然后更近一步,看你们有没有使用一些奇怪的JNI,如果没有,可以排除[3],具体到[4],对于问题[4],可以使用NMT分析。
ATP的HeapDump一般是解决问题[1]对,对于[2]可以使用NMT,我们也在规划这部分能力。
根据你提供的信息,这个问题可能有以下原因:
内存泄漏:因为你提到存在 OOM 的情况,由于
Killed process的进程 PID 是 Java 虚拟机的 PID,可能是 Java 应用程序中存在内存泄漏,导致不断分配内存,最终导致内存不足。内存使用计算问题:由于你提到了内存快照,内存使用情况看起来很大。但是要注意内存使用计算的问题,因为很多工具计算内存使用时会把内存缓存区和没有用到的内存都计算在内,所以内存使用情况看起来很大。实际上可能并不是内存不足导致的问题。
解决方法:
分析内存使用情况,借助内存泄漏检测工具进行调试。可以使用
Java VisualVM和jmap等工具查看 Java 应用程序的内存使用情况,并找到内存泄漏的源头。调整内存使用参数。可以根据实际需要,通过配置应用程序中的内存参数,来控制 Java 应用程序所使用的内存大小。
例如,可以调整 JVM 的
-Xmx参数,以控制应用程序最大可用内存大小。此外,还可以调整-XX:MetaspaceSize和-XX:MaxMetaspaceSize等参数,以控制元数据区的内存使用情况。需要注意调整内存参数时要根据具体情况进行合理的设置,同时还要进行实验和验证,避免引入其他问题。