tongchenkeji 发表于:2023-7-1 16:32:050次点击 已关注取消关注 关注 私信 请问,DataWorks创建的小时同步表,当天23点的分区,为啥是当天0点产出的?[阿里云DataWorks] 暂停朗读为您朗读 请问,DataWorks创建的小时同步表,当天23点的分区,为啥是当天0点产出的? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 DataWorks# DataWorks3343# 大数据开发治理平台 DataWorks3946
算精通AM 2023-11-27 21:26:57 1 在MaxCompute中,分区是按照UTC时间进行划分的,而UTC时间与北京时间存在时差。因此,在DataWorks中创建的小时同步表,当天23点的分区实际上是按照UTC时间的0点进行划分的,导致您看到的分区时间比北京时间早了8个小时。 例如,如果您在DataWorks中创建了一个小时同步表,名称为my_table,分区键为dt,分区类型为string,那么当您在当天23点创建分区时,实际上是创建了一个UTC时间为当天0点的分区,分区名为dt=2022-08-01-00。这个分区包含的数据是从北京时间当天0点到1点之间的数据。 如果您需要在DataWorks中创建分区时按照北京时间进行划分,可以在创建分区时,将分区值设置为北京时间。例如,如果您需要在北京时间2022年8月1日23点创建一个分区,可以将分区值设置为dt
Star时光AM 2023-11-27 21:26:57 2 DataWorks创建的小时同步表,当天23点的分区是当天0点产出的,主要是因为数据同步的时间戳是基于数据生成的时间。 在DataWorks中,小时同步表通常是用来同步实时或近实时的数据。当数据生成后,会根据数据的生成时间进行同步,并以小时为单位进行分区。例如,当天的数据会被同步到当天对应的小时分区中。 数据生成时间通常是指数据写入数据库或数据源中的时间。当数据生成时间戳为当天的23点时,仍然会将该数据同步到当天的小时分区中。这是因为数据同步是基于数据生成时间进行的,而不是基于当前时间。所以,即使当前时间已经过了23点,但如果数据在当天的23点生成,它仍然会被同步到当天的小时分区中。 总结起来,DataWorks创建的小时同步表中的分区是根据数据生成时间来确定的,并且会将数据同步到对应的小时分区中,即使当前时间已经超过了该小时。
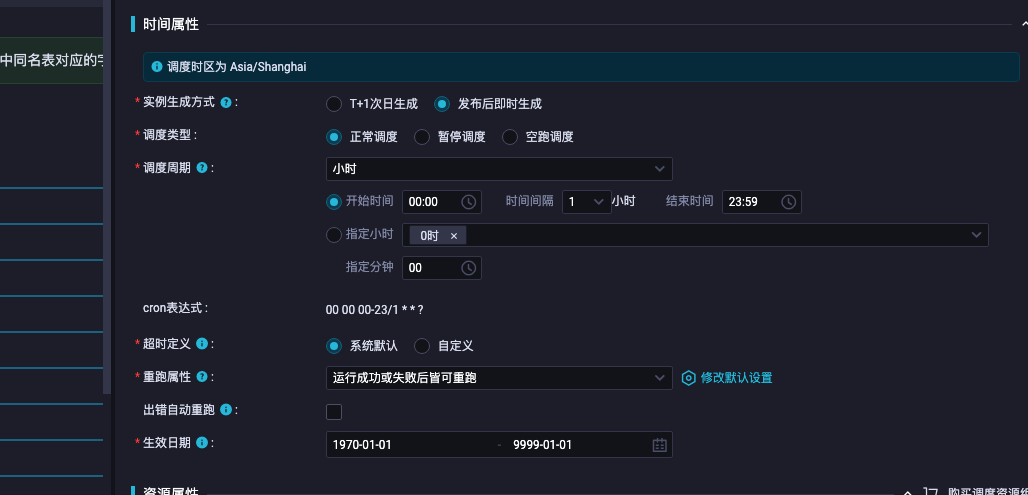
xin在这AM 2023-11-27 21:26:57 3 这个和脚本 调度参数等配置相关 发一下产出这个分区任务的运行日志哈, 天也需要减1/24 ,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
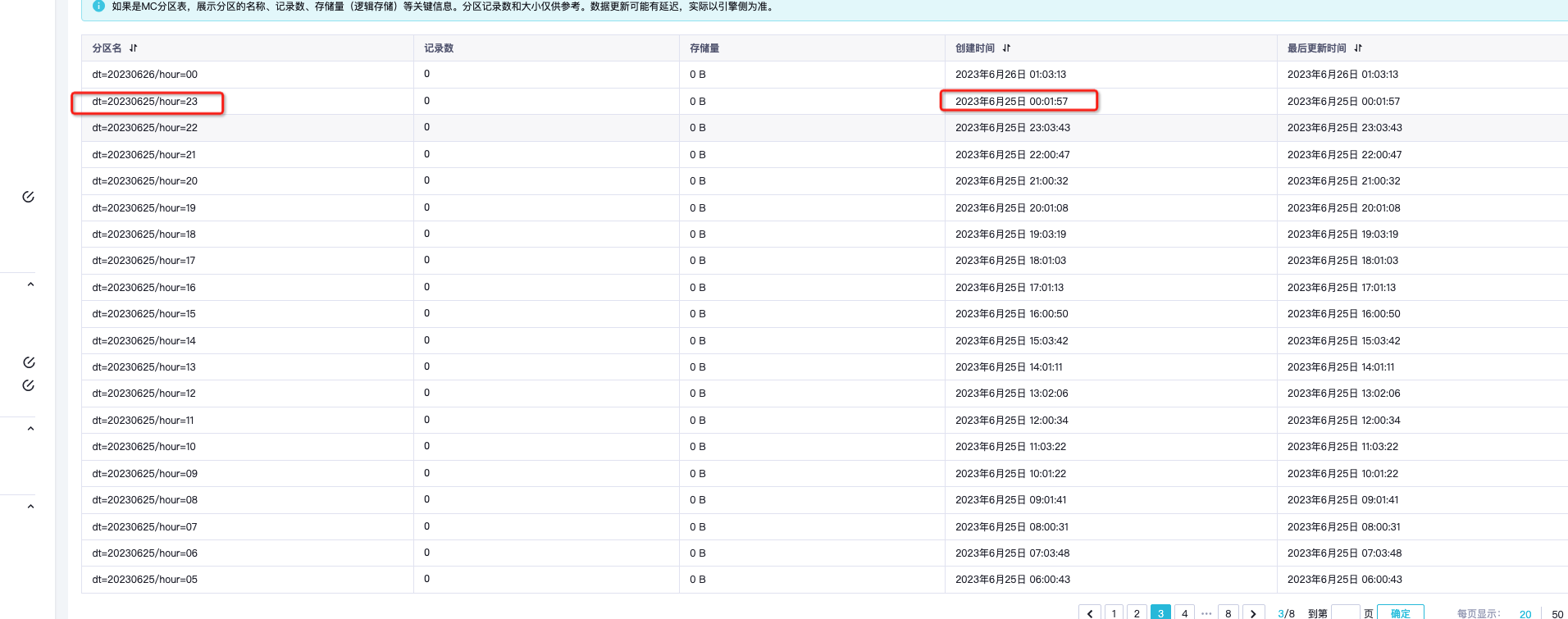
在MaxCompute中,分区是按照UTC时间进行划分的,而UTC时间与北京时间存在时差。因此,在DataWorks中创建的小时同步表,当天23点的分区实际上是按照UTC时间的0点进行划分的,导致您看到的分区时间比北京时间早了8个小时。
例如,如果您在DataWorks中创建了一个小时同步表,名称为my_table,分区键为dt,分区类型为string,那么当您在当天23点创建分区时,实际上是创建了一个UTC时间为当天0点的分区,分区名为dt=2022-08-01-00。这个分区包含的数据是从北京时间当天0点到1点之间的数据。
如果您需要在DataWorks中创建分区时按照北京时间进行划分,可以在创建分区时,将分区值设置为北京时间。例如,如果您需要在北京时间2022年8月1日23点创建一个分区,可以将分区值设置为dt
DataWorks创建的小时同步表,当天23点的分区是当天0点产出的,主要是因为数据同步的时间戳是基于数据生成的时间。
在DataWorks中,小时同步表通常是用来同步实时或近实时的数据。当数据生成后,会根据数据的生成时间进行同步,并以小时为单位进行分区。例如,当天的数据会被同步到当天对应的小时分区中。
数据生成时间通常是指数据写入数据库或数据源中的时间。当数据生成时间戳为当天的23点时,仍然会将该数据同步到当天的小时分区中。这是因为数据同步是基于数据生成时间进行的,而不是基于当前时间。所以,即使当前时间已经过了23点,但如果数据在当天的23点生成,它仍然会被同步到当天的小时分区中。
总结起来,DataWorks创建的小时同步表中的分区是根据数据生成时间来确定的,并且会将数据同步到对应的小时分区中,即使当前时间已经超过了该小时。
这个和脚本 调度参数等配置相关 发一下产出这个分区任务的运行日志哈, 天也需要减1/24 ,此回答整理自钉群“DataWorks交流群(答疑@机器人)”