tongchenkeji 发表于:2023-7-11 19:06:280次点击 已关注取消关注 关注 私信 文字识别OCR这种分区的能配置吗?[阿里云OCR] 暂停朗读为您朗读 文字识别OCR这种分区的能配置吗? 「点点赞赏,手留余香」 赞赏 还没有人赞赏,快来当第一个赞赏的人吧! 海报 印刷文字识别# 文字识别1940
六月的雨在钉钉AM 2023-11-28 3:27:13 1 你好,目前根据文字识别OCR官方结果来看的话混贴发票识别,可支持一张图片上有多张混贴图的场景,系统可自动进行分区、分类与结构化识别,没有人工设置分区的地方。
魏红斌AM 2023-11-28 3:27:13 2 基于OCR技术,票据凭证系列提供财税报销、税务核算所需的各类发票结构化识别,包括增值税发票、增值税发票卷票、火车票、定额发票、航空行程单、出租车发票、通用机打发票、过路过桥发票、客运车船票、银行承兑汇票等近二十种常见发票,及混贴发票的自动分割与识别能力:https://help.aliyun.com/document_detail/295341.html?spm=a2c4g.295338.0.i6
Star时光AM 2023-11-28 3:27:13 3 在文字识别(OCR)任务中,分区是指将文本图像划分为不同的区域,以便更好地处理和识别其中的文本内容。根据您使用的 OCR 工具或平台,有可能提供了一些配置选项来进行分区。
算精通AM 2023-11-28 3:27:13 4 OCR引擎可以使用预定义的模板或模型来识别特定区域中的文本信息,也可以通过自定义模板或模型来实现分区识别。例如,您可以使用OCR引擎提供的API接口,自定义识别区域的位置和大小,以便更精确地识别图片中的文本信息。 另外,一些OCR引擎也提供了相关工具和框架,以便更方便地实现分区识别。例如,Tesseract OCR引擎提供了Box Editor工具,可以使用该工具手动创建和编辑识别区域的位置和大小。同样,Google Cloud Vision OCR引擎也提供了相关的API接口和工具,以便更方便地实现分区识别。
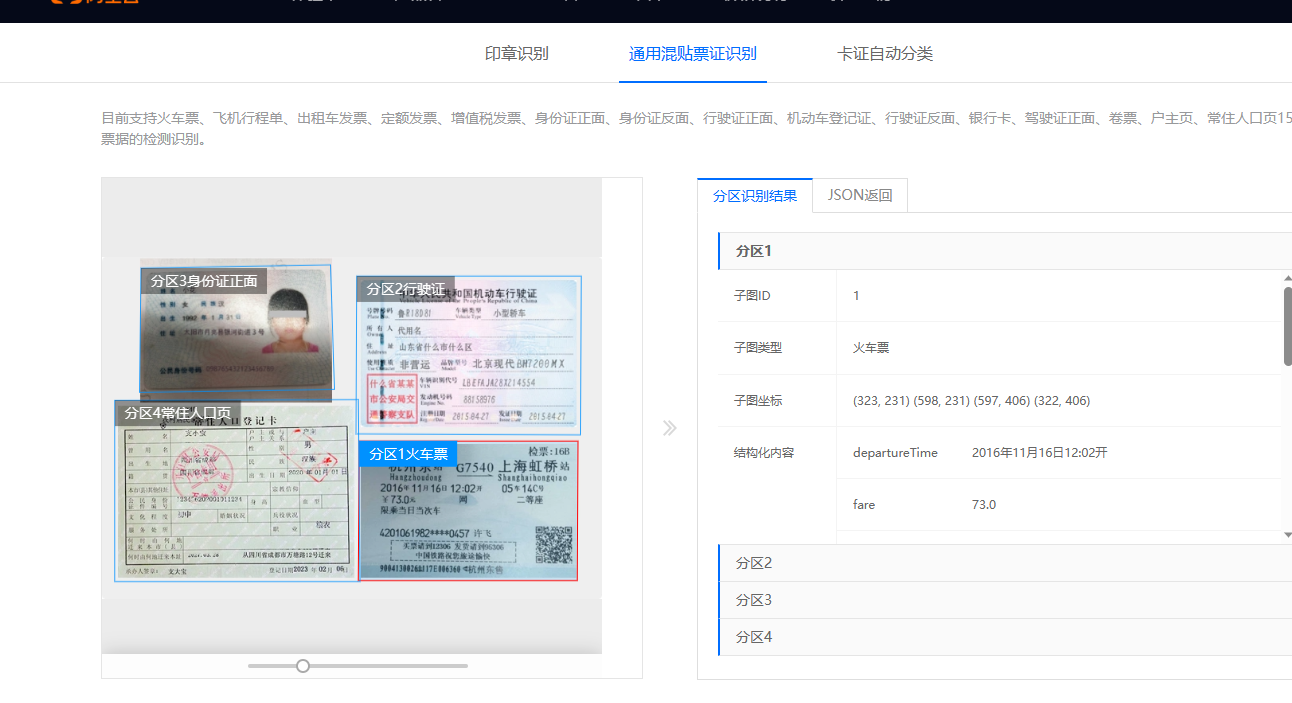
你好,目前根据文字识别OCR官方结果来看的话混贴发票识别,可支持一张图片上有多张混贴图的场景,系统可自动进行分区、分类与结构化识别,没有人工设置分区的地方。
基于OCR技术,票据凭证系列提供财税报销、税务核算所需的各类发票结构化识别,包括增值税发票、增值税发票卷票、火车票、定额发票、航空行程单、出租车发票、通用机打发票、过路过桥发票、客运车船票、银行承兑汇票等近二十种常见发票,及混贴发票的自动分割与识别能力:https://help.aliyun.com/document_detail/295341.html?spm=a2c4g.295338.0.i6
在文字识别(OCR)任务中,分区是指将文本图像划分为不同的区域,以便更好地处理和识别其中的文本内容。根据您使用的 OCR 工具或平台,有可能提供了一些配置选项来进行分区。
OCR引擎可以使用预定义的模板或模型来识别特定区域中的文本信息,也可以通过自定义模板或模型来实现分区识别。例如,您可以使用OCR引擎提供的API接口,自定义识别区域的位置和大小,以便更精确地识别图片中的文本信息。
另外,一些OCR引擎也提供了相关工具和框架,以便更方便地实现分区识别。例如,Tesseract OCR引擎提供了Box Editor工具,可以使用该工具手动创建和编辑识别区域的位置和大小。同样,Google Cloud Vision OCR引擎也提供了相关的API接口和工具,以便更方便地实现分区识别。